
Chroma Basics: Document Primitive
Building your intuition about documents in Chroma vectordb.

Chroma documents
The document name in Chroma is a bit misleading as it often does not match peoples’s world model, intuition if you will, about what a document is. The canonical form of a document is a cohesive piece of text with some structure. The document in Chroma is, in essence, a piece of text, image, or other media that fits (not always) in the context of a model. In a recent RAG-related vernacular, this is also called a chunk.
Here are the mental models I want you to take away from all this:
So what are the characteristics of a document in Chroma:
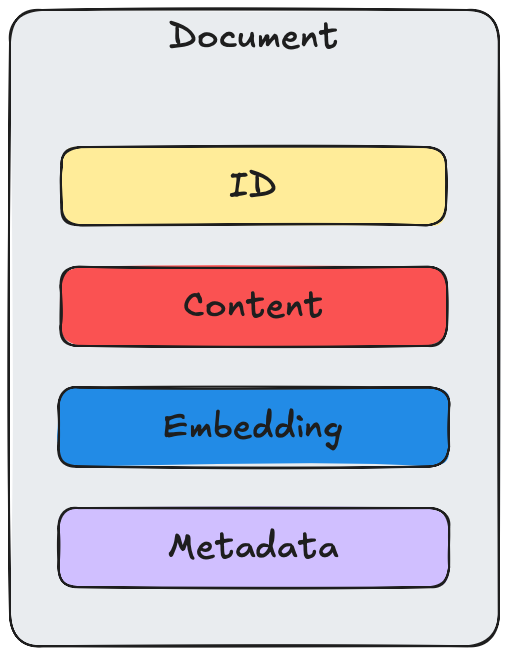
content - this is the document's actual content; most of the time, this is text; for other media, Chroma does not offer native support yet (as of 0.5.20). We'll discuss options for these down below.
id - user-defined identifier of the document. IDs are a contentious topic, so I'll have a separate article for those.
metadata - simple key-value pairs, supported types are bool, int, float, and string
embedding - the vector representation of the content (but not permanently; read on for more)
Content
We start by stating that documents in Chroma are entirely optional. If you do not need them stored in Chroma, e.g. managed externally, you can skip storing them in Chroma. This has the nice property of keeping your SQLite3 (see below) storage lightweight and super fast.
The content of the document should be represented by its embedding. However, that is not a strict requirement as Chroma decouples media and embedding representations by allowing the user to provide both document contents and embedding separately.
For single-node Chroma, the limitation on the size of the content is the same as that of text data type in SQLite3 (varies depending on the system but is generally very large). Another limitation of the size is its practicality - if it is too large, then the generation part of your app might exceed the context of the LLM. The database file (chroma.sqlite3) is also of concern for large documents.
Most folks use the content of a document to store textual content, but it is also possible to store encoded (not binary) contents such as images (e.g. base64).
Note: Distributed and hosted versions of Chroma have quota limiters, which are much more stringent in terms of content size.
Document content can also be externalized using URIs which are technically a separate construct in Chroma, but intend to serve the same purpose - represent the actual document.
Metadata
Metadata is a flat dictionary of key-value pairs (KVP). All values must be of one of the following types:
boolean
integers
floats
strings
Chroma allows some level of filtering on the metadata when making queries such as equality check, larger or smaller values, membership.
Here’s a quick list of supported operators:
equality - `$eq` and `$ne`
comparisson - `$gt`, `$gte`, `$le` and `$lte` (applicable only to floats and integer data types)
membership `$in` and `$nin`
Note: Read more on how to use the filters on the official docs - https://docs.trychroma.com/guides#using-where-filters
ID
Chroma stores IDs as text.
Note: No limits are imposed on the ID size so be careful as it will impact size of your DB and by extension its performance.
My long-term observation of how people create IDs is that they use UUIDv4. While this gives you a mostly unique identifier, it has the negative property of not being very space-efficient (find out more here).
Embedding
Embeddings are a list of 32-bit floats.
Note: Due to conversion errors it some minor precision is lost when transporting embedding over the wire. If your application relies on exact matches consider checking within epsilon range.
Document Storage
There’s a lot to be said about Chroma storage on both single-node and distributed versions. Here we’ll keep it short and focus on single-node Chroma:
sqlite3 - WAL, content, metadata and FTS
hnsw - vector storage
SQLite3
Single-node Chroma relies (as of version 0.5.20) on SQLite3 for storing and indexing documents.
Each document stored in Chroma first goes through the WAL (write-ahead log stored in embeddings_queue) before ending in the embeddings, embeddings_metadata, and embeddings_full_text_search table where all documents are stored.
As demonstrated by the above diagram, Chroma will store the ID of a document inside the embeddings table, while the content and the metadata will end up in the denormalized embeddings_metadata table.
Chroma adds the document's content to the embeddings_full_text_search virtual table, which SQLite3 will index so that you can enjoy the goodness that is the where_document filter.
HNSW
The HNSW index stores the embeddings and relational metadata as a pickle file with a dictionary lookup for relating internal HNSW index labels to embedding IDs in the SQLite3 (embeddings table).
Note: The metadata file (pickle) is created only after hnsw:sync_threshold has been reached (defaults to 1000 documents/embeddings). Until it is reached, the HNSW is kept in memory and recreated from WAL each time the collection is queried for the first time.